AI와 프라이버시의 조화: 이동 경로 데이터의 안전한 생성과 활용
생성 모델은 현재 인공지능 분야에서 매우 주목받고 있는 기술이다. 많은 사람들이 사용하고 있는 오픈AI의 챗GPT 역시 언어 생성 모델이다. 사용자가 입력한 질문이나 문장에 대해 새로운 텍스트를 생성하는 기능을 수행하기 때문이다. 이러한 생성 모델은 훈련 데이터에서 학습한 내용을 바탕으로 문장을 생성한다. 이런 작동 원리 때문에 개인 정보 유출 문제가 발생하기도 한다. 한 연구에서 GPT-3 모델을 대상으로 특정 작업에 맞게 미세 조정을 해보았더니 학습 데이터에 포함된 민감한 개인 정보를 포함하여 답변할 수 있음을 밝혀냈다. 또한 이미지 생성 모델에서도 훈련 데이터로 사용된 얼굴 사진을 그대로 재현해 내는 사례가 있었다. 이로 인해 민감 데이터를 모델 훈련에 사용할 경우, 데이터에 변형을 주어 개인 정보를 보호하는 ‘차별적 프라이버시(Differential Privacy)’와 같은 기법을 사용해야 한다.
장백철 교수(연세대학교 정보대학원)가 발표한 논문 ‘Deep learning-based privacy-preserving framework for synthetic trajectory generation’은 차별적 프라이버시를 만족하는 이동 경로 데이터를 훈련 데이터로 사용하여 실제 데이터와 유사한 이동 경로 데이터를 생성해내는 모델의 구조를 제안했다. 이동 경로 데이터는 사용자의 위치와 이동 패턴을 시간에 따라 기록하는 데이터로, 이를 통해 개인의 일상생활이나 이동 습관을 추정할 수 있어 민감한 정보이다. 그래서 앱에서 이 데이터를 수집하려면 위치 정보 수집에 대한 사용자의 동의를 얻어야 한다. 기업은 앱을 통해 사용자의 이동 경로 데이터를 수집하면 소비자 행동 분석, 위치 기반 마케팅 등에 활용할 수 있다. 하지만 사용자들은 이러한 정보를 제공하기 꺼리며, 기업은 적은 양의 데이터로는 유의미한 전략을 짜기 힘들다. 이럴 때 논문에서 제안하는 생성 모델이 유용하다. 이동 경로 데이터로 훈련시킨 생성 모델이 실제 데이터와 유사한 이동 경로 데이터를 생성해낼 수 있기 때문이다.
그렇다면 차별적 프라이버시를 만족하는 데이터란 무엇일까? 차별적 프라이버시는 데이터에 무작위로 노이즈를 더하거나 빼서 데이터 분석 결과가 특정 데이터에 의존하지 않도록 만드는 기술이다. 기존의 개인정보 보호에서는 ID와 같이 개인을 식별할 수 있는 열을 삭제하는 방법이 널리 사용되었다. 실제로 Netflix가 더 나은 영화 추천 알고리즘 개발을 위해 개인식별정보를 제거하여 영화 리뷰 데이터를 공개했다. 그런데 다른 영화리뷰 사이트에서 구한 데이터셋을 조합하여 일부 사용자를 식별해낸 유명한 연구 사례가 있다. 이는 데이터가 익명화되었더라도 역추적을 통해 개인 정보를 유추할 수 있음을 보여준다. 이러한 위험을 해결할 수 있는 방법이 바로 차별적 프라이버시다. 차별적 프라이버시는 데이터에 적절한 노이즈를 추가하여 개별 데이터가 유추되지 않도록 보호하는 동시에, 전체적인 데이터 분석 결과는 유용하게 유지한다.
예를 들어, Apple은 차별적 프라이버시를 활용하여 iPhone 사용자의 데이터를 보호하고 있다. 사용자가 입력하는 단어의 빈도를 분석해 키보드 자동 완성 기능을 개선하거나, Safari에서 가장 많이 방문한 웹사이트를 파악해 브라우징 경험을 최적화할 때도 Apple은 개별 사용자의 데이터를 보호하기 위해 노이즈를 추가한다. 이를 통해 사용자들의 개인정보는 안전하게 보호하면서도, 전체적인 데이터 분석 결과는 유용하게 활용할 수 있다.
이 논문의 주요 성과는 차별적 프라이버시를 만족하는 데이터로 모델을 훈련시킨다는 것이다. 원본 데이터가 아닌 변형된 데이터를 훈련 데이터로 삼으면 모델의 성능이 떨어지기 마련인데, 그럼에도 좋은 성능을 보인다. 변형된 데이터로 모델을 훈련시킴에도 모델의 성능을 유지할 수 있는 요인 중 하나는 데이터 변형 방법에 있다. 이동 경로 데이터 수집 시 사용자의 원본 데이터를 받지 않고, 사용자 디바이스 내에서 데이터 변형이 이루어진 후 변형된 데이터만 서버에 전송된다. 따라서 서버는 사용자에게 데이터 변형에 사용할 수식을 전달해야 한다. 최적의 수식을 전달하기 위해 다음과 같은 과정을 거친다.
처음에는 사용자가 어느 위치에 있는지에 대한 사전 정보가 없기 때문에 전체 지역을 격자로 분할하고, 사용자가 각 격자에 위치할 확률이 동일하다고 본다. 이런 일반적인 가정에서 구한 수식을 일부 사용자들에게 전달하고, 사용자들은 받은 수식으로 원본 데이터를 변형한다. 서버는 변형된 데이터를 받아서 사용자가 특정 위치에 있을 확률을 업데이트한다. 즉, 번화가와 같이 사람들이 많이 지나는 위치에 대한 확률이 좀 더 현실과 가깝게 바뀌는 것이다. 이렇게 가정을 바꾼 뒤 다시 수식을 계산하여, 나머지 사용자들에게 수식을 전달한다. 그러면 이전보다 데이터 유용성 측면에서 더 나은 데이터를 수집할 수 있다.
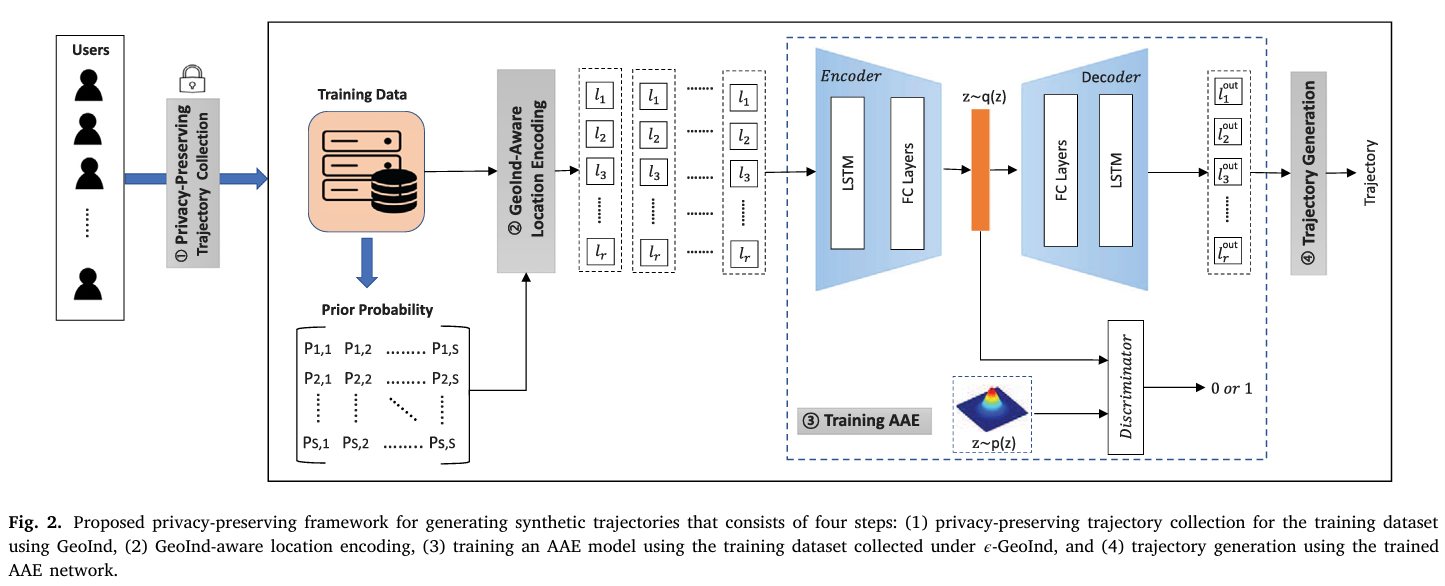
이렇게 수집된 데이터를 생성 모델이 잘 이해할 수 있는 형태로 바꾼 후 모델에 넣으면 학습이 시작된다. 이 논문에서 사용된 모델은 적대적 오토인코더(Adversarial Autoencoder; AAE)로, 오토인코더(Autoencoder)와 적대적 학습(Adversarial Learning)의 개념을 결합한 구조이다. 그래서 적대적 오토인코더의 핵심 구성은 인코더, 디코더, 판별자이다. 이 논문에서 다루는 경로 데이터를 포함하여 AI 모델에서 다루는 현실 데이터는 매우 복잡한 고차원의 데이터이다. 인코더와 디코더는 실제 데이터의 이러한 특징을 잘 반영하는 구조이다. 인코더가 복잡한 데이터에서 핵심 특징만 남겨 압축된 형태로 표현하여 통계적 추론 과정을 거친 뒤, 디코더가 데이터를 원래 형태로 복원하며 새로운 데이터를 생성한다. 그리고 판별자는 인코더와 서로 경쟁적인 관계를 형성한다. 판별자는 생성된 데이터를 실제 데이터와 구별하려고 하고, 인코더는 판별자가 그 둘의 차이를 구별하지 못하게 하는 것이 목표이기 때문이다. 이 과정을 통해 모델이 실제 데이터와 더욱 유사한 데이터를 생성할 수 있도록 훈련된다.
이 논문은 이동 경로 데이터를 안전하게 활용할 수 있는 새로운 가능성을 제시하고 있다. 특히, 차별적 프라이버시를 만족하는 데이터로도 높은 성능을 유지할 수 있다는 점은 AI 기술과 프라이버시 보호가 공존할 수 있음을 입증한 중요한 사례이다. 앞으로 이러한 기술은 사용자들이 민감한 정보를 안전하게 공유할 수 있도록 돕는 기반이 될 것이다. Apple, Google 등 글로벌 빅테크 회사들은 이미 오래 전부터 차별적 프라이버시를 활용하고 있다. 국내 기업들 또한 이러한 기술을 도입하여 개인 정보를 보호하는 동시에, 데이터 기반 서비스의 품질을 유지하는 데 활용해야 한다. 예를 들어, 위치 기반 서비스에서 사용자 데이터를 활용한 추천 시스템을 개선하거나, 헬스케어 데이터를 분석하여 개인 맞춤형 건강 관리를 제공할 때, 차별적 프라이버시 기술은 데이터 유출로 인한 사용자 신뢰 하락 문제를 해결할 수 있는 핵심 도구가 될 것이다.
* 이 글은 논문의 주요 내용을 간략히 정리한 것으로, 모든 세부 내용을 포함하지 않을 수 있습니다. 더 자세한 사항이나 명확한 내용은 아래의 원문 논문을 참고하시기 바랍니다:
Kim, J. W., & Jang, B. (2022). Deep learning-based privacy-preserving framework for synthetic trajectory generation. Journal of Network and Computer Applications, 206, 103459.
https://doi.org/10.1016/j.jnca.2022.103459
감수: 연세대학교 바른ICT연구소 노환호 연구교수
박지영
연세대학교 바른ICT연구소 인턴




